
Cloud migration is often framed as a modernization initiative. But for many businesses today, it is something more urgent: a resilience decision.
As digital operations become more central to performance, customer experience, and revenue continuity, the cost of disruption grows significantly. Downtime is no longer just a technical inconvenience. It can affect supply chains, service delivery, internal productivity, compliance, and customer trust.
That is why AWS migration and disaster recovery should not be treated as separate conversations. Businesses that approach migration without building resilience into the target environment often find that they have moved infrastructure, but not reduced risk. A stronger strategy looks beyond relocation alone and asks a more important question: how well can the business continue operating when disruption occurs?
1. Why Infrastructure Strategy Is Being Reassessed
Many organizations still operate critical workloads in legacy environments that were not designed for today’s expectations around agility, availability, and continuity. In some cases, the infrastructure itself has become difficult to maintain. In others, the bigger issue is that disaster recovery plans have not evolved at the same pace as the business.
This is one of the clearest shifts in cloud conversations today. Migration is no longer being evaluated only on performance or scalability. It is increasingly being judged by how well it strengthens operational resilience.
In practice, many businesses discover that their current environments have hidden vulnerabilities. Recovery procedures may depend on manual intervention. Dependencies between applications may not be fully documented. Recovery objectives may exist on paper, but not in a way that is realistically supported by architecture, processes, or testing.
These gaps tend to remain invisible until a disruption puts them to the test.
2. Migration Alone Does Not Solve the Problem
Moving workloads to AWS can improve flexibility, scalability, and operational efficiency. But migration on its own does not automatically create a resilient environment.
This is a common misconception. Some organizations assume that once systems are in the cloud, recovery readiness naturally improves. In reality, resilience still depends on architecture choices, workload prioritization, failover design, monitoring, governance, and regular validation.
A migration project creates the opportunity to address long-standing weaknesses, but it does not guarantee that they will be resolved. If disaster recovery is treated as a later phase, businesses risk carrying legacy issues into a more modern platform.
That is why the strongest migration strategies start with business continuity questions, not just infrastructure questions. For example:
- Which systems are truly business-critical?
- How quickly does each one need to recover?
- What dependencies could affect recovery across applications and data flows?
- Are recovery targets aligned with actual operational and budget realities?
- Who owns the recovery process across infrastructure, applications, and business teams?
These are the questions that turn migration into a resilience strategy rather than a hosting change.
3. What Businesses Often Underestimate
One of the main reasons migration and disaster recovery initiatives fall short is not the technology itself. It is the assumptions made around readiness, priorities, and execution.
Businesses often underestimate how much recovery depends on clarity. Without a shared understanding of what matters most, how systems interact, and what level of downtime is acceptable, even a well-funded cloud project can leave important risks unresolved.
Some of the most common gaps include:
▪️Unclear application criticality
Not every workload needs the same recovery model, yet many organizations have not formally aligned technical recovery priorities with business impact.
▪️Underestimated dependencies
Applications rarely operate in isolation. ERP platforms, analytics layers, third-party integrations, identity services, and reporting tools often rely on each other in ways that become critical during failover or recovery.
▪️Overly optimistic recovery targets
Recovery time and recovery point objectives are often set with the right intent, but without enough consideration for architecture complexity, cost, or operational realities.
▪️Limited testing discipline
A recovery plan that has not been tested under realistic conditions is still a risk. Many organizations have documentation, but limited confidence in execution.
▪️A narrow view of migration success
Projects are sometimes considered complete once workloads are live, even though true resilience depends on what happens after go-live: monitoring, optimization, incident response, and continuous improvement.
These are not edge cases. They are recurring patterns in cloud and continuity planning, and they are exactly why migration should be approached more strategically.
4. The Priorities That Shape a Resilient AWS Migration
A strong AWS migration and disaster recovery strategy is not just about moving faster. It is about making better decisions across a few critical areas.
▪️Workload prioritization and migration strategy
Businesses need to understand what they are migrating, why it matters, and which migration path best fits each workload. Some environments may be suited to rehosting, while others may benefit more from re-platforming, modernization, or a phased hybrid approach.
▪️Recovery architecture by business need
Disaster recovery cannot be one-size-fits-all. Critical systems require recovery models that reflect their operational importance, acceptable downtime, and data recovery tolerance. That means recovery architecture should be designed according to business criticality, not technical convenience alone.
▪️Governance and operational readiness
A resilient cloud environment depends on more than infrastructure deployment. Access controls, security configurations, monitoring, alerting, incident response processes, and ownership models all shape how effectively the environment performs under pressure.
▪️Validation and long-term optimization
Recovery readiness should be tested, reviewed, and refined over time. Migration is not the end of the journey. It is the point at which the environment must begin proving its reliability, efficiency, and adaptability.
When these priorities are addressed together, migration becomes far more valuable. It supports not only modernization, but also stronger continuity and more confident decision-making.
5. What a Structured Migration Journey Looks Like
While every organization’s path will differ, the most effective AWS migration journeys usually follow a structured lifecycle that reduces uncertainty and improves visibility.
1) Discover and assess
The current environment is reviewed to identify technical dependencies, business risks, workload priorities, and readiness gaps.
2) Plan and design
The target architecture, migration roadmap, recovery requirements, security controls, and rollback options are defined.
3) Build and prepare
The AWS foundation is established, including landing zones, networking, access controls, tooling, and baseline governance.
4) Migrate and execute
Workloads and data are moved in controlled waves, with cutover planning, replication strategies, and continuity considerations built into execution.
5) Validate and optimize
Performance, security, recovery readiness, and cost efficiency are tested and refined after migration.
6) Operate and evolve
The environment is continuously monitored and improved so it remains aligned with business growth, operational demands, and changing risk conditions.
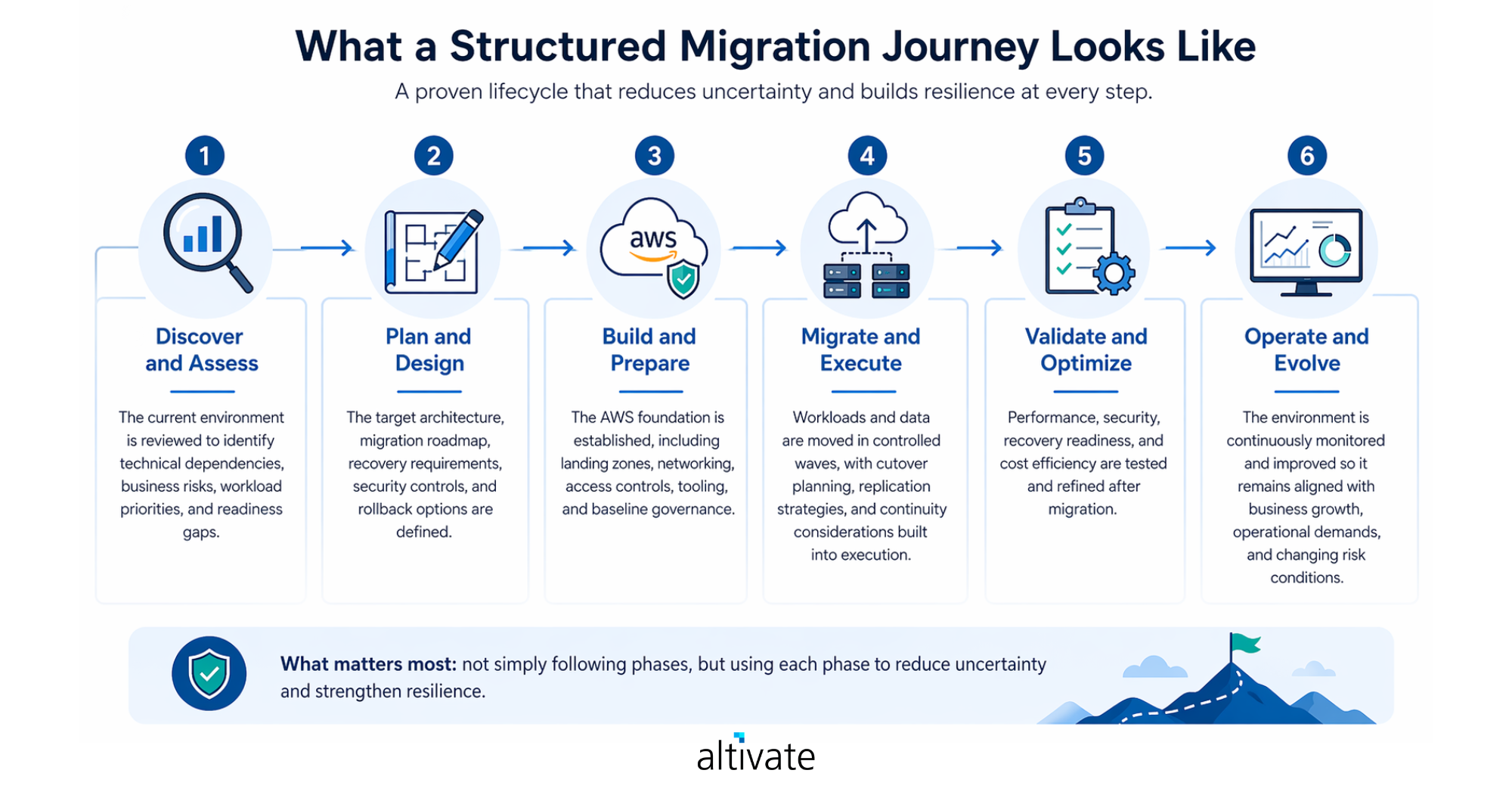
What matters most is not simply following phases, but using each phase to reduce uncertainty and strengthen resilience.
6. Why This Is Especially Important for SAP Environments
For SAP landscapes, the stakes are often higher because core operational processes depend on performance, consistency, and availability across tightly connected systems.
In these environments, disaster recovery cannot be viewed only as infrastructure recovery. Recovery readiness also depends on application behavior, database integrity, integration points, user access, and the operational discipline surrounding testing and Basis support.
That is why SAP migration on AWS requires more than technical execution. It requires a clear understanding of how business-critical processes are supported end to end, and how recovery can be achieved without introducing unnecessary disruption.
The same principle applies to non-SAP environments as well. Databases, analytics platforms, web and application servers, and legacy business systems all require recovery strategies that reflect their role in the wider enterprise. But in SAP environments, the margin for error is often smaller, making architectural and operational discipline even more important.
7. From Infrastructure Modernization to Business Resilience
When AWS migration and disaster recovery are planned together, the outcome is more than a technical transition. It becomes a business resilience initiative.
The value of that shift is significant. Businesses are better positioned to improve recovery readiness, strengthen availability, reduce operational complexity, and support more sustainable long-term optimization. Just as importantly, they move from a reactive mindset, where recovery is treated as a backup plan, to a proactive one, where continuity is designed into the environment from the start.
The organizations that gain the most from migration are not simply the ones that move workloads to the cloud. They are the ones that use migration as an opportunity to rethink risk, recovery, and operational readiness in a more connected way.
AWS migration is not only about where workloads run. Disaster recovery is not only about backup. Together, they shape how well a business can continue, recover, and adapt when conditions become uncertain.
At Altivate, we help organizations approach AWS migration and disaster recovery as part of a broader resilience strategy across both SAP and non-SAP environments.

